](http://karimbenboubaker.me/covers/ai-infrastructure-is-something-diffrent-cover.png)
TL; DR
AI infrastructure is undergoing a fundamental transformation driven by test-time compute scaling in LLMs. Traditional cloud infrastructure, optimized for IO-bound workloads, is inadequate for AI’s compute-intensive demands requiring massive memory bandwidth. This has forced a return to integrated, mainframe-style architectures like Nvidia’s GB200 NVL72, while new orchestration tools like SkyPilot and specialized neocloud providers have emerged to bridge the gap between performance and scalability.
There is something fundamental happening in computing infrastructure these days, a huge shift that makes the cutting edge of tech look backward almost 40 years. In this article, we will rethink everything you know about cloud infrastructure and its computing paradigm.
The modern AI inference and training algorithms, especially with the rise of the idea of test-time compute in LLMs, are changing the standard way cloud infrastructure usually operates. It’s forcing data centers to ditch the standard server approach and rush back towards more integrated, mainframe-style systems.
1. The Starting Point: Test-Time Scaling
The whole journey began not with hardware, but with a big shift in algorithms. There’s a concept called Test-Time Scaling, and this presents a new computing problem.
Historically, AI performance boosts came from pre-training: bigger models, more parameters, tons more data fed in up front. The focus was all on the training phase. But Test-Time Scaling added a new perspective. It transformed the computation problem into the inference phase, this means we are going to let the LLM generate more, which means we are letting the model think longer and run more calculations before giving out the result.
The groundwork for this goes back to 2022 and Chain-of-Thought Prompting Wei et al., 2022. By prompting a large language model to actually outputs its reasoning step-by-step instead of just giving the final answer, it gets drastically better at complex reasoning.
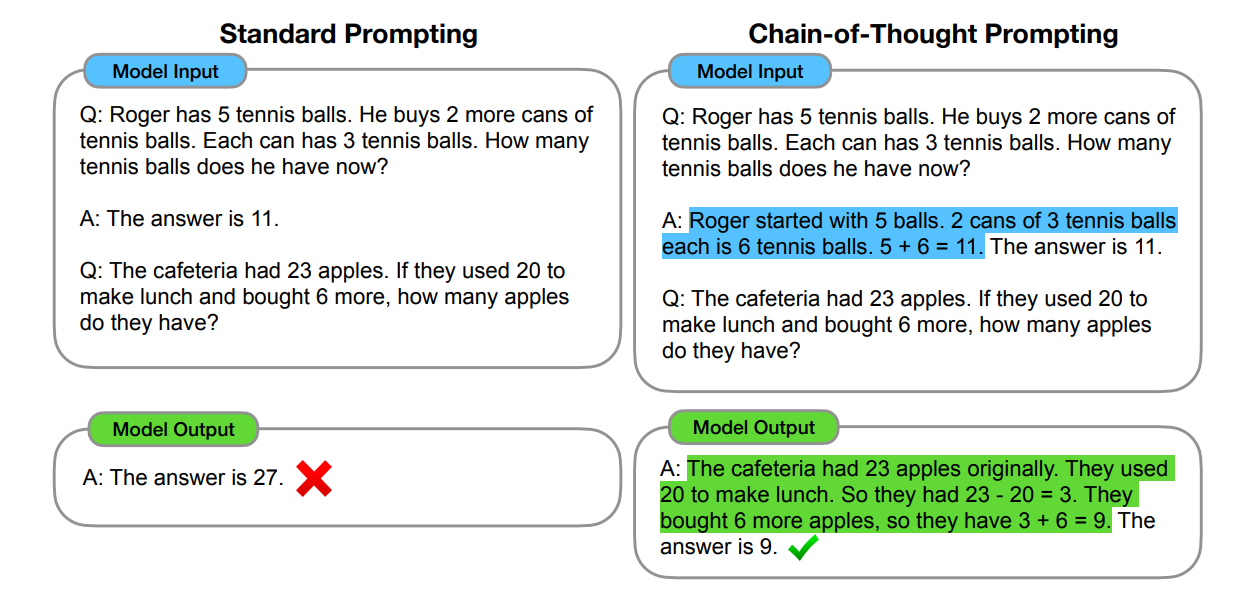
Chain-of-thought prompting enables large language models to tackle complex arithmetic, commonsense, and symbolic reasoning tasks. Chain-of-thought reasoning processes are highlighted.
While this effect is relatively new for LLMs, it’s an older effect in AI. The classic case is AlphaGo. When AlphaGo plays Go, its main neural network is already well trained, but the real magic is the computational work it does during its turn using Monte Carlo Tree Search (MCTS). This MCTS is an inference-time calculation. The interesting part is, when you take away that extra thinking time, AlphaGo’s Elo score drops from around 2,890 (way beyond human capability) down to approximately 1,500 (strong amateur), according to Silver et al., 2016.
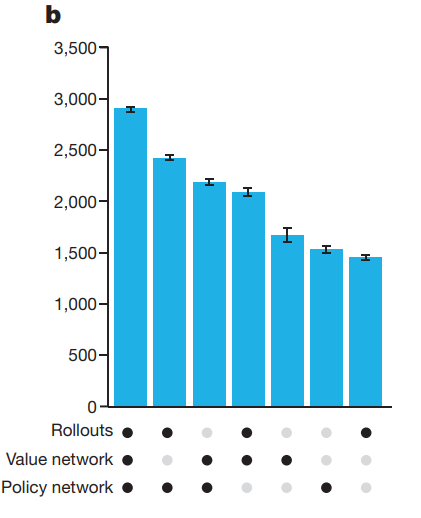
The figure demonstrates how combining search and neural networks through MCTS at inference leads to a dramatic increase in playing strength compared to using any single component alone.
We see similar huge jumps in the latest models:
- OpenAI’s o1 Model scored an incredible 83% on high-level math exams (AIME) OpenAI, 2024.
- GPT-4o, a fantastic general model, scored only 12% on the same exam OpenAI, 2024.
This is not an incremental improvement. It’s a huge jump in performance, and it’s achieved by enabling sustained, deep computation at test time.
This amazing performance boost comes at a price. The o1 model is estimated to be about 30 times slower at generating text compared to GPT-4o, and roughly six times more expensive per token Vellum, 2024.
However, the cost is justified. This kind of expensive, sustained compute allows smaller base models to actually outperform models that are 14 times larger in terms of parameters. You’re shifting the cost burden: instead of massive capital spending up front to train a giant model, you push more cost to the operational side (OPEX) during inference.
This means you need infrastructure that’s specifically optimized for that moment of thought.
2. The Core Technical Bottleneck: Memory
The AI workload profile is fundamentally different from what the internet and traditional cloud data centers were built for. Most traditional computing was optimized around IO bottlenecks (moving data around), while AI is overwhelmingly compute-bound.
In fact, the vast majority of FLOPs in transformer training come from dense matrix multiplications in MLP and attention blocks, as detailed in. The limitation isn’t storage speed or network lag in the traditional sense; it’s about the internal communication within the compute cluster and the processing capacity itself.
This leads directly to the Memory Wall problem Gholami et al., 2024:
- Peak Compute Capacity scales roughly 3x every two years.
- Data Pathways (DRAM bandwidth) only scales about 1.6x in the same period.
- External Interconnect Bandwidth linking different chips or servers scales even slower, just 1.4x.
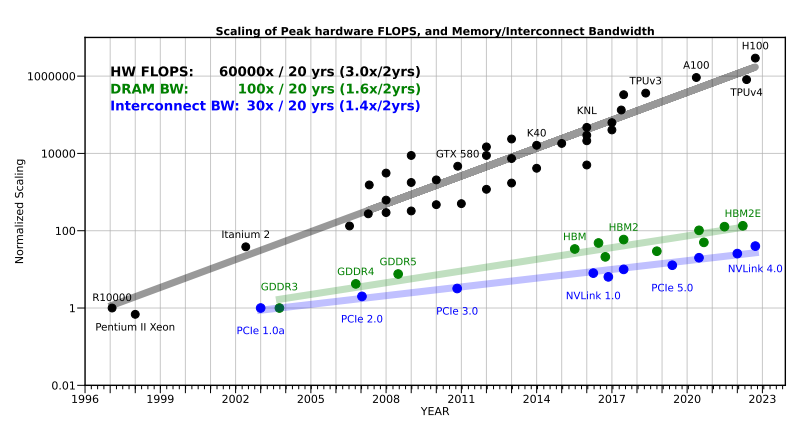
The scaling of the bandwidth of different generations of interconnections and memory, as well as the Peak FLOPS. As can be seen, the bandwidth is increasing very slowly. We are normalizing hardware peak FLOPS with the R10000 system, as it was used to report the cost of training LeNet-5.
The gap between how fast we can calculate and how fast we can get the data for the calculation is getting wider and wider.
During inference, the model works autoregressively, meaning for every single token it generates, it needs to read the entire model state, all the weights—over and over again. These operations are incredibly sensitive to memory bandwidth. If that bandwidth is choked, your inference speed drops significantly.
A single Nvidia H100 GPU internally has about 3 terabytes per second of memory bandwidth jarvislabs, 2024. Communication between GPUs needs to sustain somewhere between 400 and 900 gigabytes per second. Even going rack-to-rack, you need 100 to 400 gigabits per second. Compare that to what a typical cloud application needs, maybe 10 or 25 gigabit Ethernet.
AI needs are routinely 100 times, maybe even a thousand times higher than standard cloud traffic. If your network fabric can’t deliver that, your trillion-parameter model is just sitting there waiting for data most of the time.
This feeds into the incredible scaling crisis. Let’s take Meta’s Llama 3 405B model. Training it consumed an estimated $4 \times 10^{25}$ FLOPs, running through 27 megawatts of power continuously—roughly the power needed for a small city Epoch AI, 2024.
The projections for the frontier models expected by 2030 are estimated to require $2 \times 10^{29}$ FLOPs. The idea of supporting that kind of growth using standard general-purpose cloud infrastructure is functionally impossible Epoch AI, 2024..
3. The 2023 Cloud Crisis: When Traditional Infrastructure Hit the Wall
So, AI workloads are compute-hungry, need massive bandwidth, and are super sensitive to latency. In 2023 and early 2024, when you tried to run these jobs on standard cloud infrastructure, it broke down quickly, causing lots of money and time to be wasted.
The reliability crisis at scale became undeniable. Look at the Mean Time to Failure (MTTF) data (Kokolis et al., 2025):
- A job using 1,024 GPUs has an average MTTF of 7.9 hours.
- Scale that up to 131,720 GPUs (what frontier models need), and the expected MTTF drops to just 14 minutes.
How can anyone possibly run a training job that takes weeks or months if the cluster is statistically guaranteed to fall over every quarter of an hour?
The cost was astronomical. During Meta’s 54-day training run for Llama 3 on 16,000 GPUs, they experienced 417 unscheduled hardware failures. They estimate about $15 million in wasted compute time from restarting the massive job and reloading the state AWS, 2025.
But hyperscalers adapted to the new situation by going back to old computing paradigms.
4. The Return to Mainframe: Integrated Rack-Scale Architecture
The solution, architecturally, is this strategic retreat back to an integrated rack-scale system. It’s admitting that, sometimes, the old ways actually solve new problems better. Infrastructure engineers have effectively returned to the mainframe concept.
The prime example defining this whole trend is Nvidia’s GB200 NVL72 architecture.

A picture of the GB200 NVL72 HPC Solution.
This is not just a collection of servers; it’s engineered as one single, unified computing unit that comes as a whole liquid-cooled rack.
- The unit packs 36 Grace CPUs directly connected to 72 Blackwell GPUs.
- The system acts like one giant computer, eliminating traditional network barriers inside the rack.
- The aggregate NVLink bandwidth across all 72 GPUs is 130 terabytes per second.
This internal fabric treats all those GPUs almost like a single massive computational unit with a kind of shared memory pool. The integrated NV switch fabric keeps the direct GPU-to-GPU latency down to about 9 microseconds. This is uniform, incredibly low latency across the whole 72-GPU system.
The solution mirrors designs from the 1980s, specifically the Cray 2 supercomputer. Seymour Cray pioneered this exact integrated approach: a liquid-cooled, tightly coupled system that treated the whole machine as one unit with a massive unified common memory pool. Both the Cray 2 and the NVL72 prioritize these incredibly high-bandwidth internal communication fabrics over external connections.

A picture of the Cray-2.
Of course, cramming 72 GPUs into one chassis introduces a huge single point of failure. But it’s a calculated risk: performance gain outweighs fault exposure. Hyperscalers mitigate it by using high-reliability components and smarter fault-tolerant scheduling.
5. SkyPilot: A GPU-Aware Orchestration Tool
Hardware alone can’t fix the scaling problem; however, the existence of orchestration tools such as SkyPilot made training at a large scale more efficient and finally possible.
The problem is that running distributed AI jobs across heterogeneous GPUs, spot instances, and multi-cloud setups demands smarter scheduling logic than Kubernetes ever offered.
SkyPilot is built as a GPU-aware, cloud-agnostic orchestration layer, designed for AI and ML workloads, integrating multiple clouds and Kubernetes clusters into a single elastic supercomputer interface.
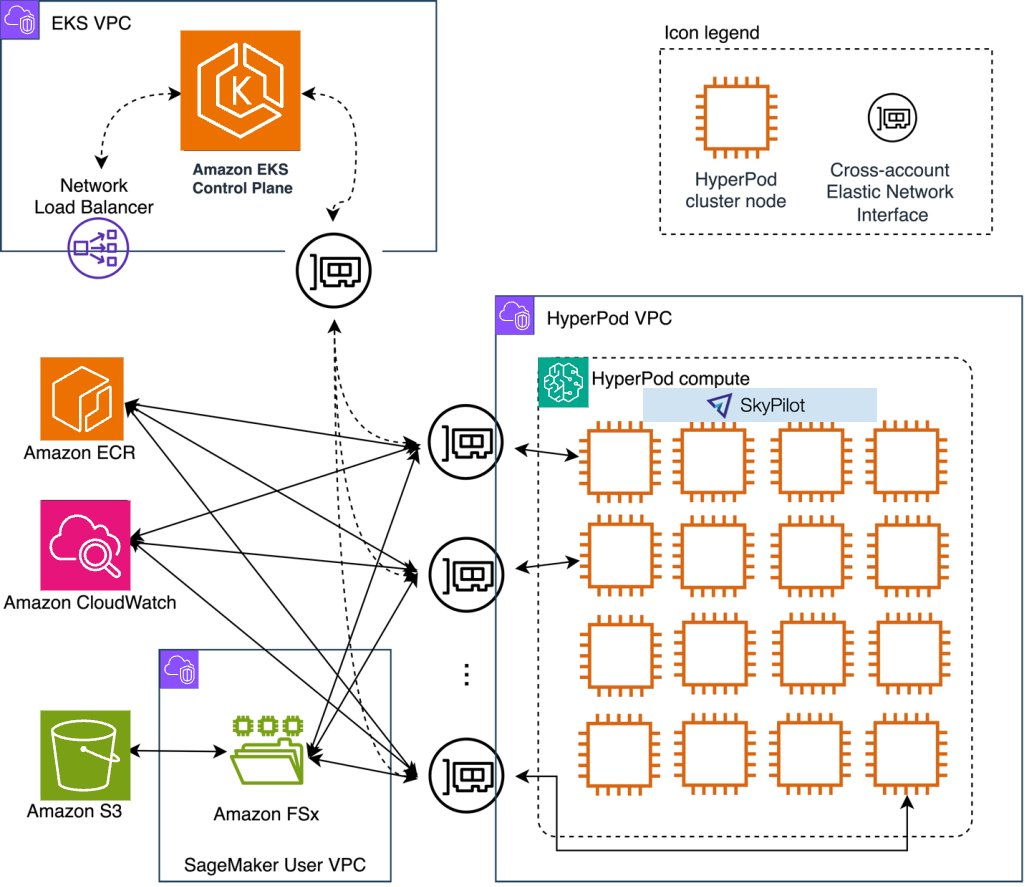
Streamlining machine learning workflows with SkyPilot on Amazon SageMaker HyperPod
The interesting part is that it includes topology-aware scheduling that considers GPU interconnects like the NVLink and InfiniBand to co-locate tightly coupled GPU jobs on nodes with high-bandwidth and low-latency connections for performance optimization.
Its design philosophy is simple: treat the cluster like a single elastic supercomputer, whether it’s spread across AWS, Azure, GCP, or a neocloud like CoreWeave or Lambda, while optimizing the memory bandwidth.
In summary, SkyPilot bridges the gap between mainframe computing and cloud-like elasticity. It’s what makes today’s hybrid GPU infrastructure usable at scale.
6. Neocloud: AI Infrastructure Pioneers
The 2023 performance crisis ignited a new wave of providers, the neoclouds. These are specialized clouds built from the ground up for AI workloads.
Classification of cloud providers
By 2025, hyperscalers had adapted, AWS Nitro and Azure’s new bare-metal VMs removed most of the “virtualization tax.” InfiniBand and EFA solved much of the networking gap. Both integrated Nvidia’s GB200 NVL72 into their offerings, while orchestration tools like SkyPilot brought intelligent scheduling to production.
So, what are neoclouds? and what are their role in the cloud industry?
Neocloud refers to a new category of cloud computing providers that specialize in offering high-performance, GPU-centric infrastructure specifically designed for artificial intelligence (AI) and other compute-intensive workloads.
They presented a risk for hyperscalers at the start of the compute bottleneck, but now their value proposition has simply shifted from solving technical problems to solving expertise problems.
They win by offering simplicity, speed, specialized support, and flexible contracts. In contrast, hyperscalers win with their integrated ecosystem (storage, databases, ML pipelines), global footprint, and ability to handle hybrid workloads that mix AI with traditional services.
This, in fact, has created a complementary reality, not a competitive war. The most revealing fact is that Microsoft is spending $10 billion with CoreWeave through 2029. Hyperscalers are becoming customers of neoclouds, using them to rapidly expand GPU capacity.
The market isn’t a zero-sum game. Neoclouds are scaling rapidly, but their growth is happening alongside hyperscaler expansion. The real outcome is that competition made high-end AI infrastructure more accessible for everyone, from startups to large enterprises.
7. Software Resilience and Scale
The problem is, even with these advances, hardware failures still persist in significant numbers. In fact, 18.7% of total GPU runtime still goes to fault recovery.
The progress of resilience relies on smarter software resilience. PyTorch Torch FT can train models to full convergence even with synthetic hardware failures injected every 15 seconds Pytorch Blog, 2025.
It’s a pattern we’ve seen before. Early computers were just as fragile, remember the lost packets and the problems of collision. Then came TCP, a simple layer of software logic that made lossless communication possible.
The same thing is happening now in compute infrastructure. TorchFT, HAPT, and fault-tolerant orchestration systems are becoming the TCP of large-scale training.
Conclusion
AI has brought significant changes to computing infrastructure, revealing the price of the abstraction paradigm adopted by the software industry in huge costs and inefficiencies that made the industry adapt and rethink the computing paradigm.
From the advent of test-time compute and scaling, the compute area has exploded in investments, conflicts, and attention. Countries and big companies are rushing into compute; the problem has even expanded into software itself, as we needed better orchestration tools that can scale distributed training with existing hardware.
While big companies are rushing to scale their models bigger and bigger with more training, other companies have taken another approach by rearchitecting these models. We may jump over these problems, and that’s what companies like Samsung are doing with their latest paper Less is More: Recursive Reasoning with Tiny Networks It redefined the architecture; future implementation and discussion are coming soon.